2025

Awesome-Story-Generation
Yingpeng Ma, Yan Ma
This repository collects an extensive list of awesome papers about Story Generation / Storytelling, exclusively focusing on the era of Large Language Models (LLMs).
Awesome-Story-Generation
Yingpeng Ma, Yan Ma
This repository collects an extensive list of awesome papers about Story Generation / Storytelling, exclusively focusing on the era of Large Language Models (LLMs).
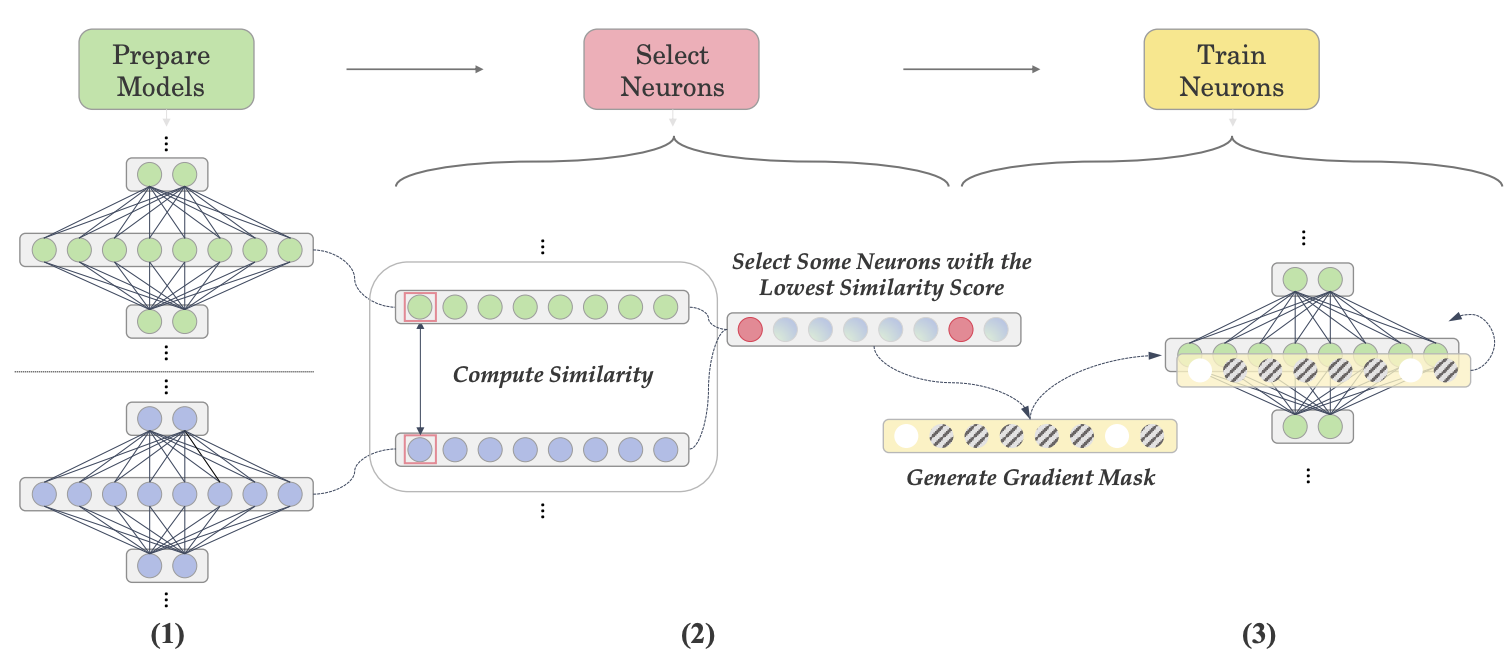
Let’s Focus on Neuron: Neuron-Level Supervised Fine-tuning for Large Language Model
Haoyun Xu*, Runzhe Zhan*, Yingpeng Ma, Derek F. Wong, Lidia S. Chao (* equal contribution)
International Conference on Computational Linguistics (COLING) 2025
Large Language Models (LLMs) are composed of neurons that exhibit various behaviors and roles, which become increasingly diversified as models scale. Recent studies have revealed that not all neurons are active across different datasets, and this sparsity correlates positively with the task-specific ability, leading to advancements in model pruning and training efficiency. Traditional fine-tuning methods engage all parameters of LLMs, which is computationally expensive and may not be necessary. In contrast, Parameter-Efficient Fine-Tuning (PEFT) approaches aim to minimize the number of trainable parameters, yet they still operate at a relatively macro scale (e.g., layer-level). We introduce Neuron-Level Fine-Tuning (NeFT), a novel approach that refines the granularity of parameter training down to the individual neuron, enabling a more parameter-efficient fine-tuning model. The experimental results show that NeFT not only exceeded the performance of full-parameter fine-tuning and PEFT but also provided insights into the analysis of neurons. Our code and data are available at: https://github.com/NLP2CT/NeFT.
Let’s Focus on Neuron: Neuron-Level Supervised Fine-tuning for Large Language Model
Haoyun Xu*, Runzhe Zhan*, Yingpeng Ma, Derek F. Wong, Lidia S. Chao (* equal contribution)
International Conference on Computational Linguistics (COLING) 2025
Large Language Models (LLMs) are composed of neurons that exhibit various behaviors and roles, which become increasingly diversified as models scale. Recent studies have revealed that not all neurons are active across different datasets, and this sparsity correlates positively with the task-specific ability, leading to advancements in model pruning and training efficiency. Traditional fine-tuning methods engage all parameters of LLMs, which is computationally expensive and may not be necessary. In contrast, Parameter-Efficient Fine-Tuning (PEFT) approaches aim to minimize the number of trainable parameters, yet they still operate at a relatively macro scale (e.g., layer-level). We introduce Neuron-Level Fine-Tuning (NeFT), a novel approach that refines the granularity of parameter training down to the individual neuron, enabling a more parameter-efficient fine-tuning model. The experimental results show that NeFT not only exceeded the performance of full-parameter fine-tuning and PEFT but also provided insights into the analysis of neurons. Our code and data are available at: https://github.com/NLP2CT/NeFT.
2023
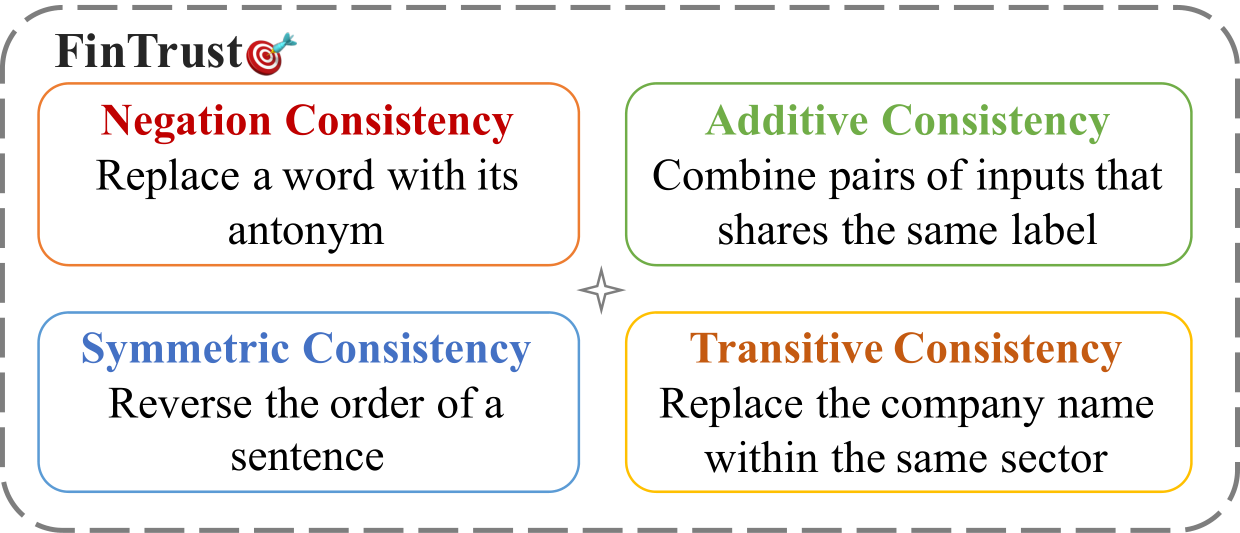
Measuring Consistency in Text-based Financial Forecasting Models
Linyi Yang*, Yingpeng Ma*, Yue Zhang (* equal contribution)
Annual Meeting of the Association for Computational Linguistics (ACL) 2023
Financial forecasting has been an important and active area of machine learning research, as even the most modest advantages in predictive accuracy can be parlayed into significant financial gains. Recent advances in natural language processing (NLP) bring the opportunity to leverage textual data, such as earnings reports of publicly traded companies, to predict the return rate for an asset. However, when dealing with such a sensitive task, the consistency of models – their invariance under meaning-preserving alternations in input – is a crucial property for building user trust. Despite this, current methods for financial forecasting do not take consistency into consideration. To address this issue, we propose FinTrust, an evaluation tool that assesses logical consistency in financial text. Using FinTrust, we show that the consistency of state-of-the-art NLP models for financial forecasting is poor. Our analysis of the performance degradation caused by meaning-preserving alternations suggests that current text-based methods are not suitable for robustly predicting market information.
Measuring Consistency in Text-based Financial Forecasting Models
Linyi Yang*, Yingpeng Ma*, Yue Zhang (* equal contribution)
Annual Meeting of the Association for Computational Linguistics (ACL) 2023
Financial forecasting has been an important and active area of machine learning research, as even the most modest advantages in predictive accuracy can be parlayed into significant financial gains. Recent advances in natural language processing (NLP) bring the opportunity to leverage textual data, such as earnings reports of publicly traded companies, to predict the return rate for an asset. However, when dealing with such a sensitive task, the consistency of models – their invariance under meaning-preserving alternations in input – is a crucial property for building user trust. Despite this, current methods for financial forecasting do not take consistency into consideration. To address this issue, we propose FinTrust, an evaluation tool that assesses logical consistency in financial text. Using FinTrust, we show that the consistency of state-of-the-art NLP models for financial forecasting is poor. Our analysis of the performance degradation caused by meaning-preserving alternations suggests that current text-based methods are not suitable for robustly predicting market information.